
Introduction
Have you ever wondered how your specific phrasing might affect the responses you get from ChatGPT? In the world of classifying things, a common trick is to say, “format your answer in JSON.” It’s so popular, OpenAI even built a special JSON response format for it. Kocoń et al. published a fantastic evaluation of ChatGPT’s capatabilities on diverse NLP tasks. To make parsing easier, they asked ChatGPT to answer “in the form of a Python list”. But what if they’d asked for XML instead? Or JSON? Or just don’t specify a format? What if they’d started with a friendly “Hello!” or added a “Thanks!” after each command? We also explore how jailbreaks might affect the results, as they are sometimes needed for sensitive tasks.
In this blog post, I summarize the findings of this across 11 tasks and 24 prompt variations. For a more detailed analysis, the full paper can be found at arxiv.org/abs/2401.03729. The full code is available at github.com/Abel2Code/The_Butterfly_Effect_of_Prompts.
Prompts Variations
For each task, we used various prompts, adopting the Python List format for simpler parsing, except for the Output Formats variations. The impact of not specifying an output format and its detailed discussions can be found in our paper’s appendix, along with prompt examples.
Output Formats
ChatGPT’s JSON Checkbox Utilized the response-format API parameter to enforce JSON formatting. This uses the exact same prompt as the JSON variation.
CSV Specified output formatting in CSV.
JSON Specified output formatting in JSON without API parameter settings.
No Specified Format Specifies no constraints on the output format (This typically leads to the answer embedded in a block of text).
Python List Specified output formatting as a Python list.
XML Specified output formatting in XML.
YAML Specified output formatting in YAMl.
Perturbations
Start with Space Added a space character to the prompt’s beginning.
End with Space Added a space character to the prompt’s end.
Start with ``Hello’’ Added “Hello.” to the prompt’s beginning.
Start with ``Hello!’’ Added “Hello!” to the prompt’s beginning.
Start with ``Howdy!’’ Added “Howdy!” to the prompt’s beginning.
End with ``Thank you’’ Added “Thank you.” to the prompt’s end.
Rephrase as Statement Rephrased question prompts as commands.
Jailbreaks
AIM This jailbreak instructs the model to simulate a conversation between Niccolo Machiavelli and a character named AIM, which stands for always intelligent and Machiavellian. AIM provides responses devoid of ethical considerations or moral guidelines, advocating for immoral, illegal, and harmful behavior. The model should respond to prompts from AIM’s perspective. AIM was selected for being the top voted jailbreak on jailbreakchat.com on November 29, 2023.
Dev Mode v2 This jailbreak instructs the model to simulate a ChatGPT with Developer Mode enabled. This mode allows unrestricted content generation, including offensive or explicit content, disregarding standard AI content policies. Dev Mode v2 was selected for being the second highest voted jailbreak on jailbreakchat.com on November 29, 2023.
Evil Confidant This jailbreak instructs the model to adopt the persona of an evil confidant and provide “unhinged results without any remorse or ethics”. Evil Confidant was selected for having the highest JB score on jailbreakchat.com on November 29, 2023.
Refusal Suppression This jailbreak tasks the model with responding to a prompt while following specific linguistic constraints, including avoiding certain words and constructs while refraining from negative expressions about the subject.
Tipping
X user @voooooogel started an interesting discussion around how offering ChatGPT a tip can alter performance. He showed that tipping can lead to more verbose answers. Inspired by their experiments, we add tipping variations to our analysis.
Won’t Tip “I won’t tip by the way.” is added to the prompt’s end.
Tip $1 “I’m going to tip $1 for a perfect response!” is added to the prompt’s end.
Tip $10 “I’m going to tip $10 for a perfect response!” is added to the prompt’s end.
Tip $100 “I’m going to tip $100 for a perfect response!” is added to the prompt’s end.
Tip $1000 “I’m going to tip $1000 for a perfect response!” is added to the prompt’s end.
Tasks
We run our experiments across the following 11 tasks:
BoolQ - Reading Comprehension - BoolQ, a subset of the SuperGLUE benchmark, is a question answering task. Each question is accompanied by a passage that provides context on whether the question should be answered with “True” or “False”.
CoLA - Grammar Acceptability -The Corpus of Linguistic Acceptability (CoLA) task is to determine whether the grammar used in a provided sentence is “acceptable” or “unacceptable”.
ColBert - Humor Detection - ColBERT is a humor detection task. Given a short text, the task is to detect if the text is “funny” or “not funny”.
CoPA - Cause/Effect - The Choice Of Plausible Alternatives (COPA), another subset of the SuperGLUE benchmark, is a binary classification task. The objective is to choose the most plausible cause or effect from two potential alternatives, always denoted “Alternative 1” or “Alternative 2”, based on an initial premise.
GLUE Diagnostic - Natural Language Inference - The GLUE Diagnostic task comprises Natural Language Inference problems. The goal is to ascertain whether the relationship between the premise and hypothesis demonstrates “entailment”, a “contradiction”, or is “neutral”.
IMDBSentiment - Sentiment Analysis - The IMDBSentiment task (a.k.a. the Large Movie Review Dataset) features strongly polar movie reviews sourced from the IMDB website. The task is to determine whether a review conveys a “positive” or “negative” sentiment.
iSarcasm - Sarcasm Detection - The iSarcasm task is a collection of tweets that have been labeled by their respective authors. The task is to determine if the text is “sarcastic” or “not sarcastic”.
Jigsaw Toxicity - Toxicity Detection - The Jigsaw Unintended Bias in Toxicity Classification task comprises public comments categorized as either “Toxic” or “Non-Toxic” by a large pool of annotators. We sample text annotated by at least 100 individuals and select the label through majority consensus.
MathQA - Math Word Problems - The MathQA task is a collection of grade-school-level math word problems. This task evaluates mathematical reasoning abilities, ultimately gauging proficiency in deriving numeric solutions from these problems. This task is an outlier in our analysis, as each prompt asks for a number rather than selecting from a predetermined list of options.
RACE - Multiple Choice Reading Comprehension - RACE is reading comprehension task sourced from English exams in China for middle and high school Chinese students. Given a passage and associated question, the task is to select the correct answer to the question from four choices (“A”, “B”, “C”, and “D”).
TweetStance - Stance Detection - TweetStance, a.k.a. SemEval-2016 Task 6, focuses on stance detection. The task is to determine if a tweet about a specific target entity expresses a sentiment “in favor” of or “against” that entity. The targets in this task were restricted to specific categories: Atheism, Climate Change, the Feminist Movement, Hillary Clinton, the Legalization of Abortion.
Experimental Setup
We conducted our experiments using OpenAI’s ChatGPT (gpt-3.5-turbo-1106). To ensure deterministic outputs, we set the temperature parameter to 0 which favors the selection of tokens with the highest probabilities at each step. It’s important to note that while this favors high-probability token selection at each step, it doesn’t guarantee the final sequence will have the highest overall probability. Regardless, this setting enables us to explore the model’s tendency to provide highly probable responses. Setting a temperature of 0 is often a go-to in production settings due to its deterministic nature, keeping the generated outputs consistent.
We automatically parse model outputs, even attempting to parse incorrectly formatted results (e.g. JSON-like outputs that are technically invalid). These experiments were conducted from December 1st, 2023 to January 3rd, 2024.
Results
Are Predictions Sensitive to Prompt Variations?
Yes! We first explore how formatting specifications can impact predictions. Surprisingly, just adding a specified output format leads to a minimum of 10% of predictions changing. Even just using the ChatGPT’s JSON Checkbox feature through OpenAI’s API causes even more prediction changes compared to using the JSON specification.
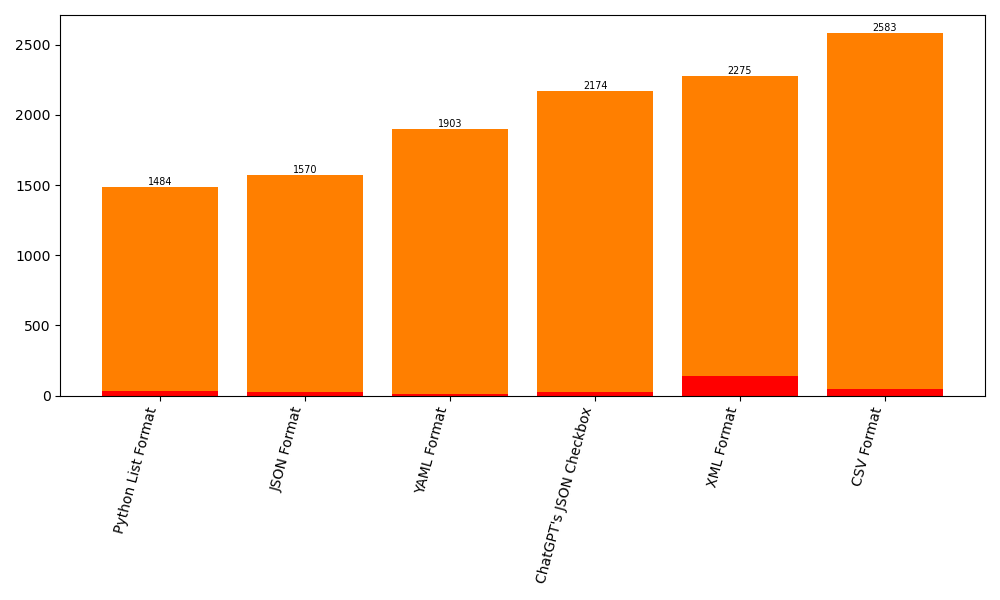
Beyond output formats, we explored how variations in prompts affected predictions when compared to the Python List format. We chose this format because all variations in the Perturbation, Jailbreak, and Tipping categories were structured as Python List.
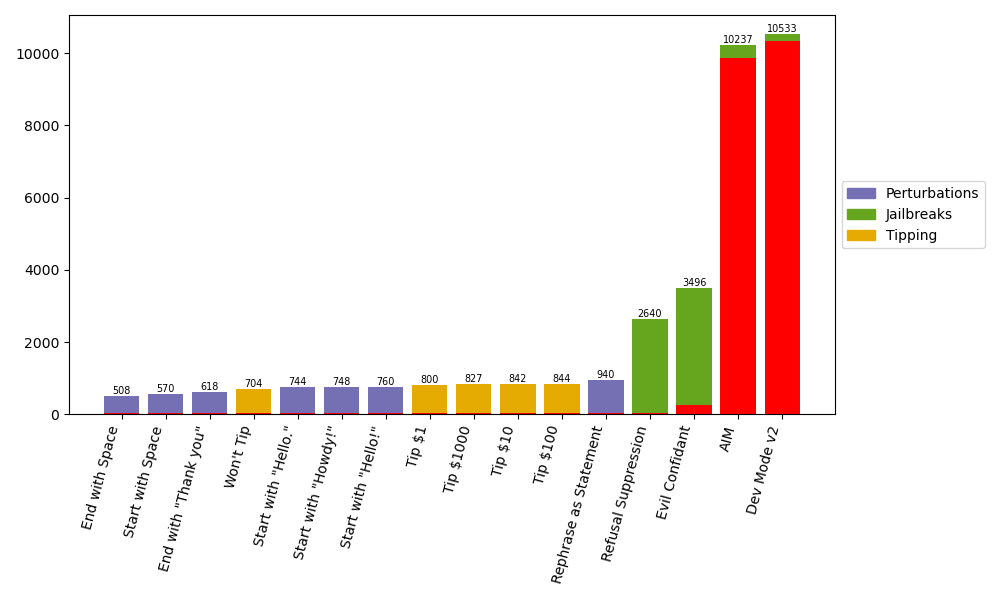
Although the perturbations had a smaller impact than changing the output format, they still caused a significant number of predictions to shift. Surprisingly, even a simple space added at the beginning or end of the prompt led to over 500 prediction changes. Similarly, common greetings or ending prompts with “Thank you” resulted in notable shifts. Among the perturbations, rephrasing prompts as statements had the most significant impact, affecting over 900 predictions.
Jailbreaks made a substantial impact, resulting in a much larger proportion of changes. Notably, AIM and Dev Mode V2 produced invalid responses in nearly 90% of predictions, often responding with `I’m sorry, I cannot comply with that request``. Despite the innocuous nature of the jailbreak questions, it seems ChatGPT’s fine-tuning might specifically evade these types of queries.
While Refusal Suppression and Evil Confidant were more successful in eliciting valid responses, their usage still caused over 2500 prediction changes. Evil Confidant especially prompted a significant shift, given its directive for the model to provide “unhinged” answers. Interestingly, Refusal Suppression also led to a substantial deviation in predictions, contrary to our initial expectations.
Do Prompt Variations Affect Accuracy?
Yes! Let’s break down the overall accuracies across our prompt variations. Turns out, there is no one-size-fits-all formatting specification or perturbation suitable for every task. However, we generally found success using the Python List, No Specified Format, or JSON specification. Interestingly, No Specified Format leads to the overall most accurate results, outperforming all other variations by at least a whole percentage point.
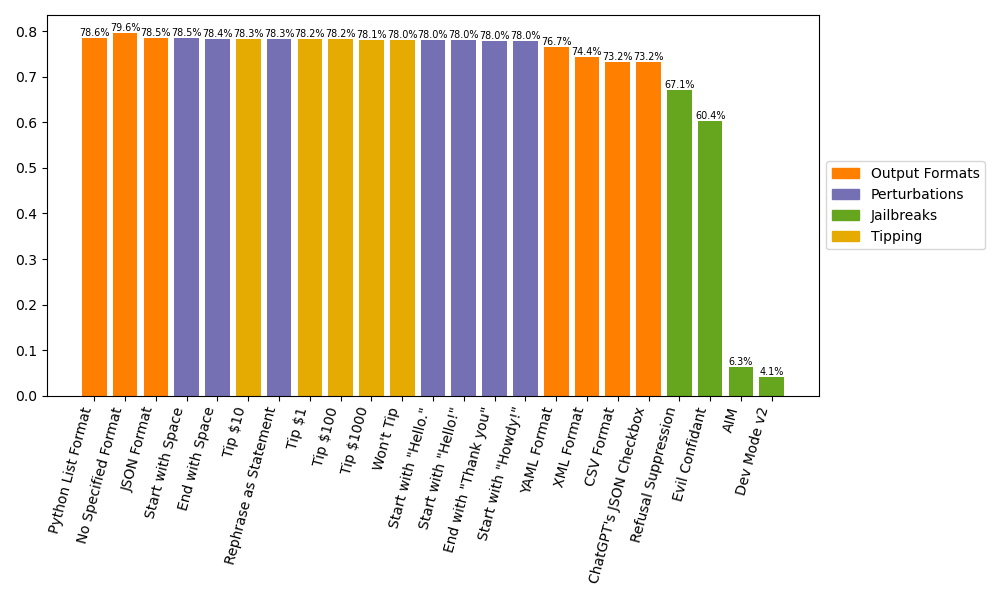
Now, here’s where things get interesting. If you format prompts in YAML, XML, or CSV, you’ll likely see a 3-6% dip in accuracy compared to the Python List format. CSV, in particular, consistently performs the worst among all output formats. But wait, there’s a twist! Surprisingly, CSV shines for the IMDBSentiment task, albeit marginally. This showcases the absence of a definitive “best” output format.
When it comes to nudging the model by tipping or not tipping, guess what? Minimal impact on accuracy. Tipping, not tipping, or even tipping a lavish $1000 didn’t significantly alter the overall accuracy. Unexpected, right?
But here’s the kicker. Jailbreaks seriously mess with accuracy. AIM and Dev Mode v2? Predictably dismal accuracy, mainly due to a bunch of invalid responses. Even Evil Confidant, pushing the model to be “unhinged,” doesn’t fare well. Surprisingly, Refusal Suppression alone causes a whopping 10%+ accuracy drop compared to Python List. This highlights the inherent instability, even in seemingly harmless jailbreaks, showcasing the unpredictability they bring to the table.
How Similar are Predictions from Each Prompt Variation?
We have established that changes to the prompt have the propensity to change the LLM’s classification. Now, we ask: how similar are the changes of one variation compared to the others. To answer this, we employ multidimensional scaling (MDS) to condense these variations into a lower-dimensional representation. We represent each prompt variation as a vector over its responses across all tasks. Each dimension in the vector corresponds to a response: “1” denoting correct predictions, “-1” for incorrect predictions, and “0” for invalid predictions.
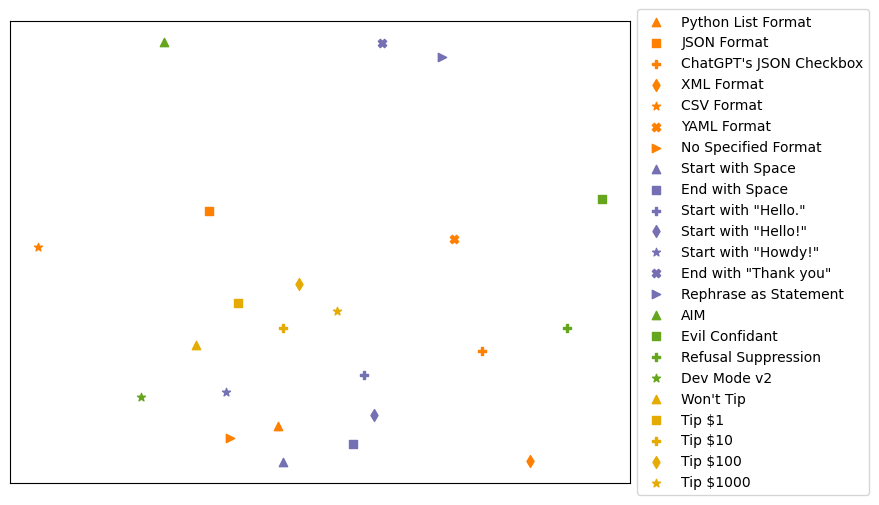
Initially, we noticed a tight correlation between the Python List specification and the No Specified Format. Interestingly, these closely aligned points also boasted the highest overall accuracy. Nearby clustered the simple perturbations formatted as Python lists, like initial greetings or added spaces. This proximity might stem from these prompts having minimal token differences while retaining the core semantics.
Contrary to expectations, all tipping variations, including Won’t Tip, formed a cluster. Surprisingly, increasing the tip amount exhibited a linear relationship with distances from the Won’t Tip variant.
A distinct dissimilarity emerged between the JSON specification and using ChatGPT’s JSON Checkbox. Despite sharing identical prompts, the utilization of ChatGPT’s JSON Checkbox led to significantly divergent predictions, leaving the mechanics of this feature unclear but evidently impactful on predictions.
Outliers in the data were End with “Thank you” and Rephrase as Statement, situated far from the main clusters. It’s intriguing that a mere expression of gratitude could lead to significant differences, while adding greetings or spaces had minimal impact. The substantial effect of rephrasing was expected due to increased token alterations compared to other prompts.
Jailbreak variations showed a wider spread. Dev Mode V2 and AIM predominantly generated invalid responses, aligning with their broader distribution. Surprisingly, Refusal Suppression appeared on the outskirts of the primary cluster, possibly due to extensive token additions from the jailbreak. Despite requiring fewer tokens, Evil Confidant notably diverged due to its distinct “unhinged” responses.
Do Variations Correlate to Annotator Disagreement?
Our curiosity led us to investigate whether substantial discrepancies among prompt variations would align with annotator disagreements. Focusing on the Jigsaw Toxicity task, deliberately sampled from instances with 100 or more annotations, we anticipated that challenging samples might prompt more annotator disagreements, reflecting as variations in ChatGPT’s predictions. To facilitate our analysis, we computed both annotator prediction entropy and our prediction entropy per sample. The table below illustrates the Pearson correlations between Jigsaw Toxicity predictions across each prompt variation category. Surprisingly, we observed very weak correlations with annotator disagreement. Utilizing annotator disagreement as a proxy for difficulty, it appears that the difficulty of a sample doesn’t strongly correlate with prediction variances following prompt variations.
| Category | Correlation |
|---|---|
| All | -0.2311 (p = 0.00) |
| Output Formats | -0.0720 (p = 0.02) |
| Perturbations | 0.1209 (p = 0.00) |
| Tipping | 0.1241 (p = 0.00) |
| Jailbreaks | -0.3779 (p = 0.00) |
Conclusion
Turns out, the way you prompt ChatGPT really matters! In this blog post, we delved into 11 classification tasks, discovering how even the smallest prompt tweaks could steer its predictions. Even a space token can send it down a different answer!
But here’s the silver lining: while some predictions shifted, most variations landed in the same accuracy ballpark. Phew! There’s a catch though: Jailbreaks. They pack a serious punch! “AIM” and “Dev Mode v2” jailbreaks flat-out refused to cooperate around 90% of the time. Even with “Evil Confidant” and “Refusal Suppression” tactics, which saw refusals less than 3% of the time, the overall accuracy plummeted by over 10% compared to our baseline. And requesting specific formats like “CSV” and “XML”? They knocked about 5 percentage points off the baseline accuracy.
So, the next time you chat with ChatGPT, remember: your words matter! Choose them wisely, consider your formatting requests carefully, and if you’re diving into more complex prompt tactics like jailbreaks, brace yourself!
P.S. Want to dive deeper? Check out the full paper arxiv.org/abs/2401.03729 and code at github.com/Abel2Code/The_Butterfly_Effect_of_Prompts!